Research
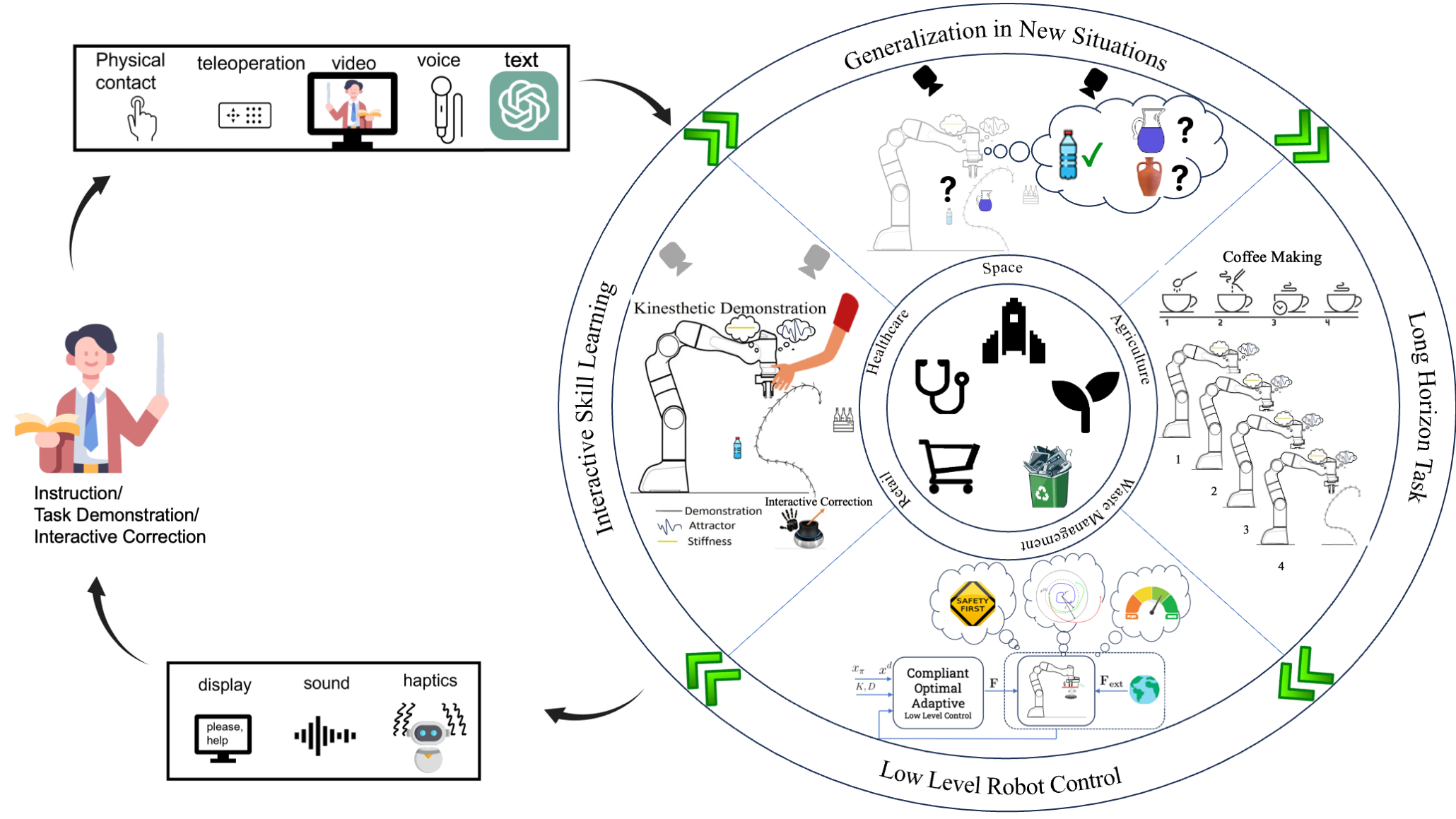
Our mission is to build the theoretical foundations and practical algorithms that let robots learn from, adapt to, and collaborate with people in unstructured, real-world environments. We draw on machine learning, optimal control, and formal methods to make robotic systems data-efficient, generalizable, and provably safe during physical human-robot interaction. The themes below summarize our current directions and representative results.
Interactive Reinforcement Learning
Reinforcement learning (RL) and learning from demonstration let robots acquire manipulation skills directly from interaction and human guidance. The hard cases are long-horizon, contact-rich tasks and learning robustly from limited, imperfect human data. We address the first with Impedance Primitive-Augmented Hierarchical RL (ICRA'25), which gives a high-level RL policy a low-level action space of parameterized impedance-control primitives, yielding compliant, contact-rich skills over extended task sequences. For the second, we make imitation robust to the quality of the teacher: Beyond the Teacher (ICRA'26) leverages mixed-skill demonstrations to learn policies that tolerate inconsistent human teachers, RISE (IROSW'25) uses stochastic latent encodings for robust imitation, and PACER (CoRLW'25) curates demonstrations by task progress to curb the compounding errors that destabilize behavior cloning.

Foundation Models for Robotics
Foundation models, including large vision-language models (VLMs) and, increasingly, vision-language-action (VLA) models pretrained on web- and robot-scale data, supply semantic priors and broad generalization that can ground robot behavior in natural language and perception. We study how to turn these priors into natural, flexible human-robot interaction. Our work on OVITA (RA-L'25) harnesses pretrained foundation models to adapt reference trajectories from open-vocabulary language instructions at execution time, producing interpretable, parameterized edits to robot motion without any task-specific retraining.
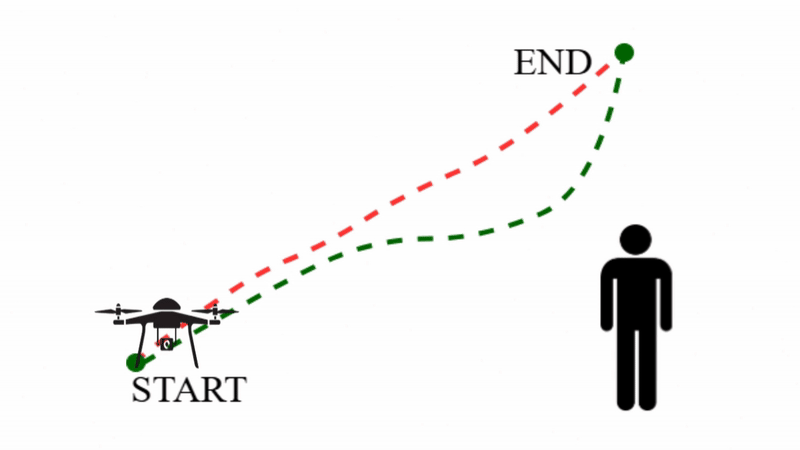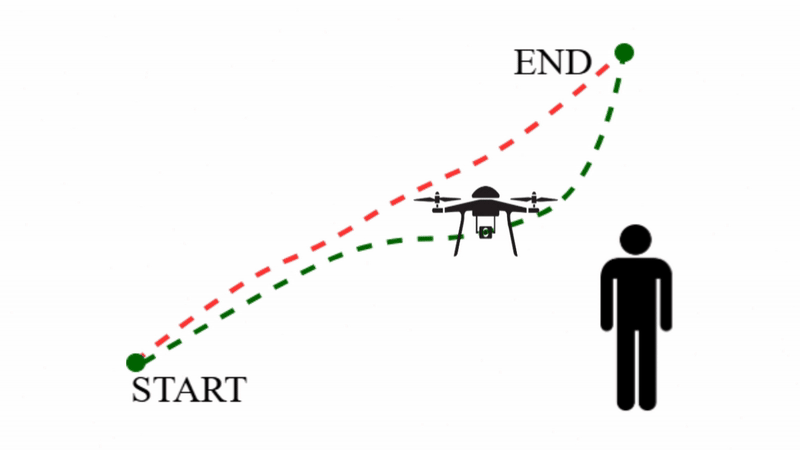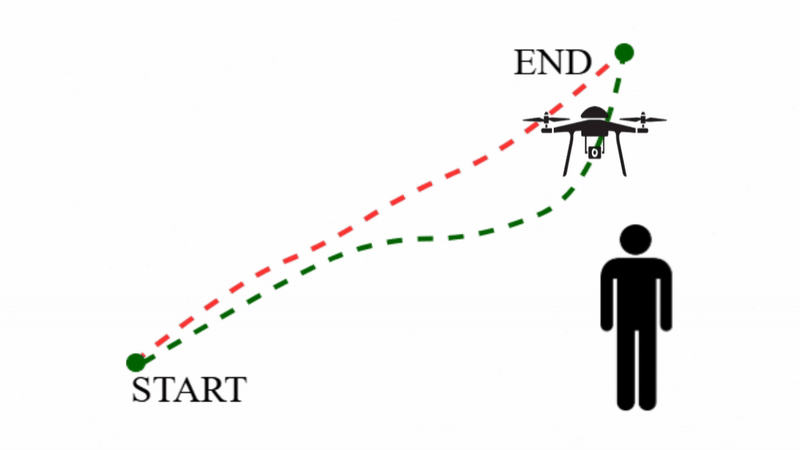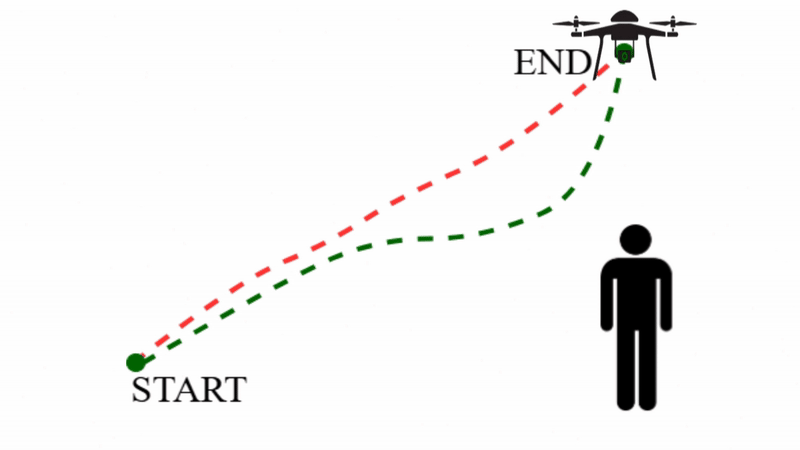
Safe and Compliant Human-Robot Interaction
When robots make physical contact with people, behavior must be both compliant and provably safe, with guarantees that hold during interaction and not just on average. We bring formal methods and control-theoretic certificates together with learning to enforce this. SafeDMPs (ICRA'26) embeds Signal Temporal Logic (STL) safety specifications directly into Dynamic Movement Primitives, so that adaptive motions remain provably safe during physical human-robot contact, while certified RL for variable impedance control (ICRA'26) pairs RL with Lyapunov-based stability certificates to modulate impedance optimally with guaranteed stability. We also learn safety directly from offline data, without online interaction: Safe Flow Q-Learning (RLC'26) couples reachability analysis with flow-based policies for offline safe RL, and V-OCBF (TMLR'26) learns value-guided control barrier functions that act as safety filters.

Optimization and Optimal Control
Optimization and optimal control offer principled, data-efficient ways to synthesize controllers and motion policies, often with stability or generalization guarantees. Our Adaptive Critic (T-CST'24) framework uses approximate dynamic programming with neural value-function approximation to learn near-optimal controllers for uncertain manipulators online, without explicit system identification. Keypoint parameterization with transportation (optimal-transport) maps (T-RO'25) yields motion policies that generalize one-shot to novel object configurations, and ST² (RA-M'26) teaches robots long-horizon manipulation by composing skills from sequential human demonstrations.

3D Vision, SLAM and World Models
Acting in unstructured environments demands spatial understanding from 3D reconstruction, simultaneous localization and mapping (SLAM), and world models that capture both geometry and semantics. We are building active-perception pipelines that tie real-time scene reconstruction and object-level mapping to manipulation planning. A first step in this direction, AffordMatcher (CVPR'26), learns object affordances in 3D scenes from visual signifiers, connecting 3D scene understanding to where and how a robot should act in complex, cluttered spaces.